量化实习 v2丨Day 49:更高、更快、更强
条评论今天仍旧在处理期限结构因子,但是大部分时间在做另一件事儿:优化回测框架的 Position 类的性能。
起因是在研究策略的时候,发现用自己开发的回测框架运行常常耗费大量时间,一次回测甚至要 3 秒。究其原因,发现性能瓶颈主要出现在 Position 类生成持仓数据的过程。这个过程会在一个 for 循环中处理每一日的持仓,而且仅使用 pandas 的方法来处理数据,效率极低。
于是我决定将这一过程也向量化。首先,需要每日将因子值正反排序,并取其 rank。由于 numpy 中没有类似的方法,于是我刚开始的想法是诉诸于 scipy。但是测试之后发现,scipy 并没有为 rank 的计算带来很高的效率提升。对源代码层层拨茧抽丝,发现 scipy 实现时完全使用 numpy 进行计算,而 pandas.DataFrame 的 rank() 方法本来就是用 Cython 实现的,自然不会有很大的性能差异。因此,rank 的计算就交给 pandas 本身了。后续,我将数据由 DataFrame 转换成 NDArray,一通操作,又处理了一大堆 bug、warning 和计算结果不一致的问题,最后终于将函数改写成效果一样,但性能差异巨大的另一个函数。经过测试,新的函数计算效率能够达到原函数的几十上百倍。
有了快速回测的函数,终于可以愉快地对策略调参了。这个期限结构的策略真的很有意思,它带来的信息不会迅速衰减,因此即使按照 20 日的频率调仓都能够带来很好的正收益,而且曲线相当稳定,即使考虑了一定的交易费率。我仔细检查了因子逻辑,应当是没有使用到未来数据。而再用公司的回测框架测试,效果也十分可观。
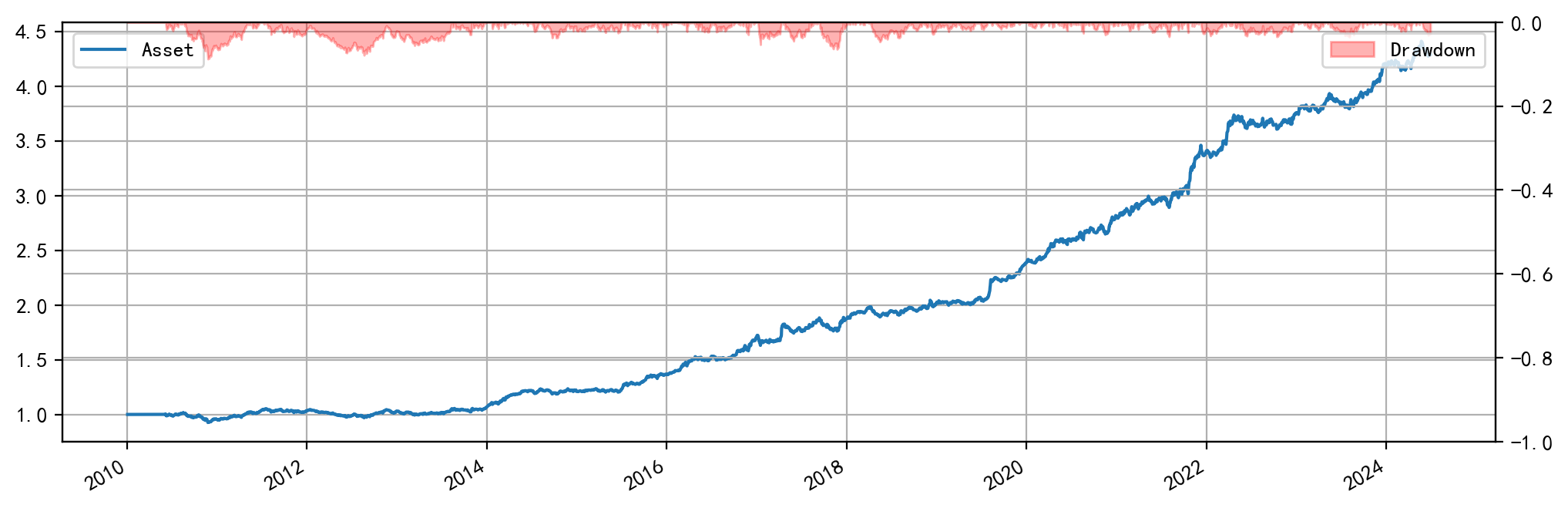
这件事相当神奇,因为一个这么简单的因子按道理不会有这么漂亮的收益。而这不是最令我费解的部分。诡异的事情在于,如果要得到这样好的收益,我必须要将因子值做成研报所展示的因子的相反数。也就是说,研报上的逻辑要做多时我应该做空,研报上的逻辑要做空时我则应该做多。这不太正常,尽管我对于这一因子的经济逻辑仍然理解得不是很清楚。但是应该不是我的回测框架的问题,因为我的因子值即使在公司的回测框架上也能得到很好的收益,乃至 2 以上的夏普比率。
明天要再好好检查一下因子逻辑是否有问题,不行就跟带教讨论一下好了。